Editor: Chris Douce
Contents
Workshop Review Jim Buckley compiles a witness report on PPIG 2003.
PPIG ‘04 Enda Dunican provides us with some preliminary information regarding next years workshop.
Book and Journal Reviews - Chris Douce reviews The Elements of Java Style by Allan Vermeulen et. al.
Conferences, Workshops and Call for Papers
Newsletter Paper The Intangible System: What does an Executing Software System Look Like? by Pamela O’Shea.
Spotlight on PPIGers where you are and what you are doing.
Musings from the Trenches - Chris Douce puts fingers-to-keys to contemplate slices of life as a professional software developer.
Links beyond A number web links that may be of interest to PPIG members
It’s Doddery Fodder …but is it Art? Another foray into the humourous, bizarre and interesting by Frank Wales.
Editorial
Welcome to the Summer 2003 edition of the Psychology of Programming newsletter.
It was nice to see so many of you at this years workshop. Many thanks go to the workshop organisers at Keele University for doing a fantastic job, creating an entertaining, energetic and successful event.
In this issue, Jim Buckley presents a brief description of the last workshop. This is then followed by some information about PPIG ‘04, to be hosted by Enda Dunican. More information will be available in due course.
Pamela O’Shea, like Jim, also from the University of Limerick presents her PhD research proposal. Her article discusses some of the main issues with Software Visualisation Tools and some reasons why they may not have been widely adopted in industry.
This issue also sees the return of two previous columns: spotlight on PPIGers, and musings from the trenches. We can also find (now) old favorites, reading as fresh and as entertaining as ever. Again, many thanks goes to Frank for his doddery fodder. I personally think that his latest contribution is his is his funniest yet.
Many thanks also go to the other contributors. Remember, this is your newsletter. If you have read a paper, book or discover a new journal that you feel may be of interest to the PPIG community, please do tell us.
We would especially like to hear from the psychologists, sociologists, linguists and architects among you. This is a field that is fascinatingly interdisciplinary. Do tell us of your methodologies, views and opinions. We would love to hear from you. Sometimes it feels as if the programming ‘P’ within PPIG speaks louder than the psychology ‘P’. Both are of interest, and both undeniably important.
We are also interested to hear of how old PPIG members are getting along, even if you have drifted away into other academic avenues of endeavor. If you remember us at all, do get in touch.
As I wrote within the last newsletter, please feel free to send me inclusions, comments (and corrections?) at any time. I am always happy to hear from you.
Looking forward to seeing you all next year!
Chris Douce
Chrisd(at)fdbk.co.uk
Workshop Review
Psychology of Programming Interest Group (PPIG) 2003
8-10 April 2003, University of Keele, UK.
By Jim Buckley, University of Limerick, Ireland.
PPIG 2003 was co-located with EASE this year in the very pleasant surroundings of Keele University. The papers ranged from keynote talks through full technical papers, to ‘work-in-progress’ papers that described an exciting array of current work.
Chris Hundhausen gave the first keynote speech of the workshop. He described his work on ALVIS: an ALgorithm VIsualization Storyboarder, and the empirical studies that underpinned its development.
These empirical studies showed that traditional algorithm visualization software typically ‘requires students to put inordinate amounts of time into… irrelevant activities’, and ‘discourages students and instructors from engaging in meaningful conversations about algorithms’.
ALVIS, in contrast, facilitates rapid construction of low-fidelity, interactive visualizations of algorithms. Because the tool is of low-fidelity, users are less reluctant to change the visualizations during discussion of the algorithm.
In Judith Segal’s keynote talk, she argued convincingly that the empirical software engineering community should learn from the HCI community and consider more qualitative studies, in an attempt to better model practice. She proposed that such studies should be used to complement, if not supplant the ’traditional scientific method’ of formal controlled experiments in order to get a more realistic understanding of practice.
All of the technical papers were of a very high standard. In particular, [Sharp et al.]’s portrayal of the tensions that can arise when adopting a software quality system was particularly interesting.
Also notable were [Good and Brna]’s proposed measuring schema for assessing programmers’ comprehension of their systems and [Kuittinen and Sajaniemi]’s discussion of variable roles in teaching programming.
Of the work-in-progress papers [Clarke and Becker]’s was perhaps the most intriguing. It described their studies at Microsoft’s usability laboratory relating experienced programmers’ usage of class APIs with the cognitive dimensions. Specifically, they related the APIs to the cognitive dimensions associated with certain ‘programmer-types’, and thus tried to improve the API for its intended users.
Also notable were [Tucker]’s description of the problems students have when learning, [Jadud]’s pedagogical experiences when using language design for Lego Mindstorm robots, and [Petre]’s elaboration of the insights experienced designers have when addressing difficult design problems.
All in all, PPIG this year was a very worthwhile experience, with interesting talks, interesting people and really good food. In fact, the after-dinner drinks weren’t bad either! Many thanks must go to Marian Petre, and the programme committee for organizing such a successful event.
PPIG ‘04
Enda Dunican will be hosting the next PPIG workshop. It is proposed that the workshop will be held at the Institute of Technology, Carlow, Ireland. The proposed dates are between Monday 5th April 2004 and Wednesday 7th April.
More information regarding his institute and the surrounding area can be found by visiting the following links:
Further details about the next PPIG workshop will be made available through the announce mailing list when more information is available.
Book and Journal Reviews
By Chris Douce
The Elements of Java Style
The Elements of Java Style
by Allan Vermeulen et. al.
Cambridge University Press, 2000
ISBN 0-521-77768-2
The title of this short pocket book has been derived from Kernighan and Plauger’s classic ‘Elements of Programming Style’ published back in 1978. Despite a second edition of the book being published in eighty-nine, I found that it was an incredibly difficult book to get hold of.
The issue of programming style was one of the many that led me to the area of the psychology of programming. Very early in my programming career I discovered that a number of developers around me were using different formatting conventions. Like many before me, I became incredibly irritable when presented with the rigors of Fortran which required certain characters to be in particular column positions - something to do with punched cards, apparently.
I decided there were a number of dimensions of style: naming, white space, function size, use of declarations. Was there such an issue as an ‘optimal’ style, I wondered? Is there a form that allows programming error to be minimised?
Styles are like habits. They can be formed by technology, by sweat through syntactic rigor. I am sure that many of us would have heard of software folklore stories (see also Lindsay Marshall’s PPIG'02 paper) about an old programmer who insisted on writing line numbers, even though the compiler no longer supported them.
Recently, I found myself challenged. ‘Why don’t you put your assignments and declarations together? This reduces lines of code!’ Embarrassed, I came to realise that this was due to my Pascal upbringing, and the pickiness of its compiler for efficiency reasons. My style, it seemed, was to some degree static due to programming indoctrination, my sense of aesthetics not moving with the programming times.
This is a book that can be read in around two hours, but its digestion will take considerably longer. It begins with truisms like, ‘use familiar names’ and ‘question excessively long names’, to good object-oriented advice such as ‘use nouns when naming classes’ and ‘make object methods carry out only one operation’.
There are some elements that I take objection to - the use of curly braces, for example, and the adoption of two space characters per indent instead of one tab (an explanation is offered, but one that I’m not convinced about!). Using this offends my senses. I prefer my own idiom.
The authors are pragmatic about comments. They ask you to use comments so that automatic documentation can be formed from source code through the documentation of classes and interfaces. They also insist that comments should reflect codebase reality, using the third-person narrative form, and to illustrate (with references, perhaps) why the code is doing what it is doing, not what it is doing.
A number of familiar references are provided, along with a range of web links. Writing Solid Code by Maguire and Code Complete by McConnell both make an appearance.
The Elements of Java Style strikes me as a miniature refactoring text, especially when it addresses some object-oriented issues. Whilst getting hot under the collar about their bracketing (and naming) conventions, I remember what a colleague said to me a couple of weeks ago when he asked me to review some Java code that he was battling with: ‘I don’t care what the programming style is - as long as it is consistent’, and don’t come across comments like, ’this appears to work, but I do not know why’.
Second hand copies of the The Elements of Programming Style can now be found on Amazon.
Have you read a book that you think that others may find interesting? If so, please do tell us about it. We’re crying out for some reviews of psychology books! Send all reviews and ideas to chrisd(at)fdbk.co.uk
Conferences, Workshops and Call for Papers
Step Workshop
Following on from the highly successful joint PPIG/EASE workshop in Keele at Easter, why not join with the Empirical Software Engineering community to discuss issues pertaining to evidence?
The PPIG community has done important work on the tools used by software engineers, for example, on programming languages and notations. However, PPIG shares a concern with the Empirical Software Engineering community that this work is not sufficiently informing software engineering practice.
One reason might be that the work is not sufficiently visible to practitioners; another might be scepticism as to the external validity of our results. Academic studies may seem to the practitioner to be far removed from the rich context of practice. How, then, do we design studies which are relevant to practitioners and which produce evidence which is both convincing and applicable in practice?
Do come and share your ideas at the workshop that we are running in Amsterdam on Friday 19th September as part of the Software Technology and Engineering Practice Conference.
David Budgen
Agile Development Conference
June 25-26, 2004
Salt Lake City, Utah, USA
The Agile Development Conference is an integrated, 4-day conversation about techniques and technologies, attitudes and policies, research and experience, the management and development sides of agile software development.
The agile approach focuses on delivering business value early in the project lifetime and being able to incorporate late-breaking changes in requirements by accentuating the use of rich, informal communication channels and frequent delivery of running, tested systems, and attending to the human component of software development.
The Agile Development Conference gives attendees access to the latest thinking in this domain and bridges communities that rarely get a proper chance to exchange ideas and thoughts, bringing together researchers from labs and academia with executives, managers, and developers in the trenches of software development. The Agile Development Conference is not about a single methodology or approach, but rather provides a forum for the exchange of information regarding all agile development technologies.
We invite you to share your knowledge and experience via the submission of Research Papers and Experience Reports for the 2004 Agile Development Conference. Research Papers present significant contributions to the field of agile software development, advancing the state of the art, influencing the framework of thought in the field, or, perhaps, criticizing current agile development methodologies in a reasoned fashion. Experience Reports contain first-hand information and reflection, offering valuable knowledge gained through hands-on experience in real projects. Papers may present a view of what works, what doesn’t, and why, in employing agile methods in software development projects.
The following are example paper topics, but submissions are by no means limited to themes listed here:
-
Research on new, or existing, agile development (AD) methodologies and approaches, including Adaptive, Crystal, DSDM, FDD, Scrum, XP.
-
Case studies, empirical studies involving agile development or a particular technique, tool, or approach; What has worked; What hasn’t? What sort of gains (if any) was seen in projects employing an agile approach?
-
Does AD scale? to development in the large (including multi-person/multi-year/multi-component projects)? to safety-critical, life-critical, mission-critical systems?
-
Critical comparisons/evaluations of alternative AD methodologies; is there a ‘more perfect world’ that involves picking and choosing the best from each?
-
Business analyses – e.g., is AD cost-effective and justified?
-
Management of AD projects, teams, and individuals therein
-
Relationships between AD and user-centered design (UCD)
-
Cognitive aspects of AD; Cognitive aspects of software development (psychology of programming and design) and consequences for AD
-
Patterns and AD; Patterns for AD
-
Introducing AD into existing IT organizations; reactions of developers and executives to AD
-
Sociology of AD; Are there people-oriented problems involved in applying AD methods, and how can they be solved? Sociology of software development and consequences for AD
-
Relationships between CSCW (computer supported cooperative work) and AD
-
Tools for AD, computer-based and others.
More information can be found at the conference website. Authors are invited to submit papers by January 30, 2004.
Conference Chair: Todd Little, Landmark Graphics
Research Papers Chair: Sherman R. Alpert, IBM Watson Research Center
Experience Reports Chair: Andy Pols, Pols Consulting Ltd
Newsletter Paper
The Intangible System: What does an Executing Software System Look Like?
An Approach to improving Program Comprehension using Software Visualisation within the Debugging Environment
Pamela O’Shea
Software Visualisation and Cognition Research Group
Department of Computer Science and Information Systems
University of Limerick, Ireland
pamela.oshea(at)ul.ie
Supervisor: Dr. Chris Exton
Abstract
For decades the same limited set of questions have been asked within debuggers, but what about all those other questions that are asked but cannot be answered within the context of today’s debuggers? For example, what does the data flow for this project look like in real-time? Or what are the variable values that affect the value of variable X here?
The debugging environment has been stepped-over and ignored for years without taking into consideration the needs of current software engineers. This research re-focuses on the needs of modern software engineers and plans an investigation into whether Software Visualisation is supportive in answering such questions using abstractions of the software system.
1. Introduction
At present, there is no standard such as the Unified Modelling Language (UML) that can be used to describe how an executing software system should be represented on screen. The dynamics of an Object-Oriented system reveal quite a lot about the nature of the system and much of this information cannot be gathered until runtime [Smith and Munro 2002], [DePauw et al 1998], [Gargiulo and Mancoridis 2001].
Software Visualisation has the most potential in the dynamic representation of an executing system. The fact that this avenue of research is generally unexplored is discussed by [Smith and Munro 2002], where the authors make the argument that “Software is inherently dynamic, yet much of the analysis and comprehension processes focus entirely on the static source code of the software”.
As a result, the software engineer is currently missing a large piece of the puzzle by only having static information and minor profiling information available when debugging. This article discusses Software Visualisation (SV) as a potential solution to this problem, where integration of static and dynamic views is prioritised along with support for switching between comprehension strategies.
It is interesting to note that many of the SV papers that describe tools, do not make any claims on program comprehension. This is surprising, since the goal of software visualisation is to aid understanding and reduce the burden of comprehension.
Why then are somany unsupported claims made regarding the benefits of software visualisation? It can hardly be considered not relevant but instead program comprehension may not be seen as a priority when in fact it should be used to influence the requirements phase of the SV tool and again upon tool completion to validate its effectiveness.
This research plans to take the less travelled road by not only implementing the proposed SV tool but by also conducting an empirical study that will be performed before the tool is written, along with a second study once the tool is complete. In this way, the experimental results will influence the design of the tool ensuring that program comprehension is kept in mind at all stages and not ignored during the valuable requirements phase.
1.1 Issues with current SV Tools
Software Visualisation tools are quite abundant both commercially and academically. However, when a closer examination is taken it can be seen that there is a lot of noise in the results. For example, many tools fail to meet one or more of the following criteria which may be acceptable for their own purposes but make them unsuitable when the target audience is professional software engineers.
- Source code alterations are needed to create the visualisation, e.g. calls to a custom built visualisation library provided by the tool.
- The tool does not scale well to larger industrial sized programs.
- The tool only applies to a language that is not popularly used in industry, for example, Pascal, LISP, etc. While these languages have their niches, they are not targeting the average programmer in industry who uses C, C++, Java, Python etc.
- No dynamic or runtime information is provided.
- Only one aspect of the system is considered, for example, the tool may concentrate on control flow or software architecture and ignore data flow and source code views etc.
- Occlusion can occur easily.
- The tool is difficult to install and/or requires a specific library or operating system.
- The tool is stand-alone and not integrated into a debugger or integrated development environment and as a result the user must not only switch views but also programs and the two have no means of being synchronised together, for example, as the user steps through the debugger the visualisation cannot be updated.
To examine an executing software system in its entirety, a large number of SV tools would have to be used together. That is, SV tools are specialised, performing one job or another. For example, Tool A will present control flow information, Tool B will present data flow and source code views, and another Tool C will present the software architecture view. While there are many excellent SV tools available, integration problems arise as each tool supports different languages and platforms, while others for example, are propriety.
It is perfectly natural that each tool is built to perform a certain job, after all one tool alone cannot be expected to do all and decide to show both static and dynamic information of an executing system at varying degrees of abstraction, such as, source code, control flow, data flow, state, functional, runtime relationships, software architecture etc.
However, the professional software engineer is receiving a very muddled picture of software visualisation at present and this may be one of the reasons for its lack of adoption in industry. At least academically, researchers should be combining their effort into an open-framework that is integrated into an environment currently used by software engineers, such as Eclipse [Eclipse] or Netbeans [Netbeans]. This would allow for tool designers to concentrate on implementing their view of a system and to release it as another SV view within the context of the debugger. That is, the user should be able to choose from a variety of views within the one environment.
A proposed solution will be described in the next section where a monitoring framework for Java is integrated into the Netbeans IDE and can be build upon to provide the levels of abstractions over time.
2. Proposal: SV Abstractions
2.1 Background
2.1.1 What types of Queries are typically required during Maintenance and Debugging?
[Pennington 1987a], [Pennington 1987b] outlined program summaries as a means for assessing program comprehension. These categorisation of statements have been expanded by [Good 1999a], [Good and Brna 2003]. The original categorisations from Pennington can be used as a starting point to investigate which queries are commonly used by software engineers.
- Function, the overall goal of the program, e.g. “What is the purpose of the program ?”, “What does the program do ?”.
- Control Flow, information on the temporal sequence of events occurring in the program, e.g. “What happens after X occurs ?”, “What has occurred just before X ?”.
- Data Flow, transformation which data objects undergo during execution, including data dependencies and data structure, e.g. “Does variable X contribute to the final value of Y?”.
- Operations, information about specific actions which take place in the code, generally corresponds to a single line of code or less, e.g. “Does a variable become instantiated with a particular value ?”.
- State, time-slice descriptions of the state of objects and events in the program, e.g. “When the program is in state X, is event Y taking place, or has object Z been created/modified ?”.
2.1.2 Can Software Visualisation Help ?
It is essential that the various comprehension strategies should be supported in a development tool. The following section highlights the calls made by researchers for support of these comprehension strategies.
[Storey et al 2000], states that a software maintenance tool needs to:
- Support a combination of comprehension strategies
- Provide a means to easily switch between strategies while solving a task
- Reduce cognitive overhead as the program is explored
[von Mayrhauser and Vans 1993], also states that all comprehension strategies must be supported as well having the ability to switch between each of them.
[Mullholland 1997], found that the following should be supported:
- mapping between Control Flow information in the SV and the code
- mapping between Data Flow information in the SV and the code
- gaining a clear temporal perspective of the execution within the SV
- keeping track of Control Flow even during complex phases
This leads to support for SV abstractions, the following is a brief overview. SV abstractions define a number of levels or views of an executing software system. Pennington’s work is used as a foundation to define the basic views such as, control flow, data flow, state. Other views are added to incorporate dynamic information such as the system in execution view.
All of these views are built upon the source code view, which is the lowest abstraction. The control flow view is the next and so on until the view furthest away from the source code is reached, which is the most abstract view called the software architecture view.
It should be noted that these views are just an outline and many more exist that have not been described. An empirical study will be performed in other to gather data on the most commonly used abstractions during maintenance, it is hoped that other views will be found and identified. The abstraction views/levels are not numbered as there are many gaps that need to be filled through empirical studies, as can be seen in Figure 1. A more detail description is provided in the next Section.
2.2 Description
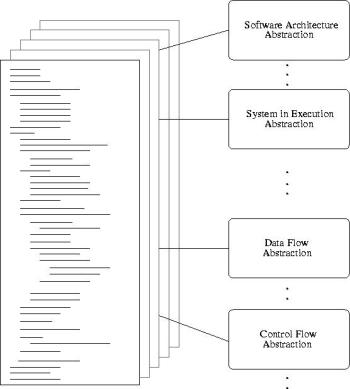
Figure 1: SV abstractions
From Figure 1, a software system (source code files shown on the left) can be examined at many levels of abstraction. For instance, the highest abstraction is the software architecture overview, next is the system in execution in realtime, further down the abstractions is the data flow view and control flow views.
All of these views are hidden in the documentation and source code. In the case of source code, all this information is located within the same file(s), for example, control flow abstraction and data flow abstraction can only be separated in the mind of the software engineer after reading the source or by using tools, for example, such as aiCall [aiCall], to gather control flow information and a separate tool such as Jinsight [Jinsight] for the data flow. Even this poses problems, as both these tools support different languages!
Software Visualisation can be used to abstract away these layers of the system and present them to the user for further investigation. The Abstractions will be extracted from the source and the instrumented Java Virtual Machine (JVM) in order to present the views to the user.
In this way, both static and dynamic information can be integrated to provide a more complete picture. Since the views increase in their level of abstraction from the source code, switching between the comprehension strategies will be made possible. For example, top-down comprehenders have the option to explore the system from the software architecture view and bottom-up comprehenders have the option to explore the system from the source code and control flow views.
The question is, which abstraction or abstractions are best suited to aid the comprehension for the industrial software engineer? With this knowledge, SV tools can be developed or adapted to emphasise this abstraction and ensure it presents the information in the most appropriate form.
As the abstractions increase upwards, the distance from the source code is increased. For example, the control flow abstraction can contain parts of the source when presenting its information, whereas the software architecture abstraction is the most abstract containing no source code. Each abstraction must support user defined queries and allow interactive exploration of the system.
For the planned investigation, it is hypothesised that the levels nearest the source code will provide the most comprehension of the system. For example, if this is the case then it is worthwhile building a tool to allow chunking [Shneiderman and Mayer 1979] and annotations of the source code etc.
2.3 Empirical
2.3.1 Measuring Comprehension
The coding scheme from [Good 1999a] and [Good 1999b] will be used as a measure of comprehension. This measurement of comprehension was chosen due to its ability to measure levels of abstraction which is highly appropriate for this research. For example, Data Flow and Control Flow statements can be measured and compared, the same is true for other abstraction levels.
2.4 Designing for the Software Engineer
A preliminary investigation will be carried out in order to gather requirements for the tool. Program summaries, Video and sketches will be among the data gathered. Program summaries will be used as a measure of comprehension while the sketches are to aid in empirically establishing the abstraction levels.
The tool will then be implemented using the abstraction levels identified from the study along with support for switching between these. For example, if the study shows that there is a lot of switching from source code descriptions to control flow descriptions, then both these levels will be integrated to allow for such switching.
The implementation will consist of a monitoring framework for Java programs which has already been implemented using the JPDA [JPDA] as a means of keeping track of the executing system. Java was chosen due to the ability to monitor events in its virtual machine and due to its popularity in industry. This will be integrated into an open IDE such as Eclipse or Netbeans, where future abstractions can be added and tested as they are implemented.
Once the tool is complete, a post study will take place where the tool can be evaluated using professional software engineers. These results will verify if the tool produces any improvement in program comprehension in comparison to existing tools.
3. Conclusion
As discussed previously, the software visualisation field has a gap in the question of how to represent an executing system. The authors approach, abstractions, has been discussed and a number of these abstractions will be implemented and integrated into the NetBeans IDE.
The abstractions will allow the software engineer to examine slices of the system, for example, to examine the control flow or the data flow or both or any other combination of the abstractions.
Once the most commonly used abstractions have been established a large proportion of the research will involve establishing appropriate techniques for those abstractions, for example, while a SeeSoft-like view may be appropriate for the source code level, it is not entirely appropriate for the software architecture view.
The need for more empirical evidence was also discussed, especially in the area of dynamic software visualisation. A contribution will be made to this empirical body of research where the results will feed the requirements phase for the visualisations, then another study will be performed on professional software engineers in order to verify the effect of the visualisations.
Finally, your feedback and criticisms are very much welcomed, especially in identifying other commonly used abstractions that should be implemented, or your ideas on which techniques are suitable for a particular abstraction.
Bibliography
[aiCall] aiCall Software Visualisation Tool, Available, “http://www.absint.com/aicall/".
[DePauw et al 1998] DePauw, W., Lorenz, D., Vlissides, J., Wegman, M., “Execution Patterns in Object-Oriented Visualization”, USENIX, 1998.
[Eclipse] Eclipse IDE, Available, “http://www.eclipse.org/".
[Gargiulo and Mancoridis 2001] Gargiulo J., and Mancoridis, S., “Gadget: A tool for Extracting the Dynamic Structure of Java Programs”, SEKE, 2001.
[Good 1999a] Good, J., “Programming Paradigms, Information Types and Graphical Representations: Empirical Investigations of Novice Comprehension” Ph.D. Thesis, University of Edinburgh, 1999.
[Good 1999b] Good, J., “VPLs and Novice Program Comprehension: How do Different Languages Compare ?”, IEEE Symposium on Visual Languages, Tokyo, Japan, September 13-16, 1999.
[Good and Brna 2003] Good, J., Brna, P., “Toward Authentic Measures of Program Comprehension”, In Proceedings of Joint Conference of EASE & PPIG, Keele University, April 8-10th, 2003, pp. 29-49, 2003.
[Jinsight] Jinsight, IBM Research, Available: http://www.research.ibm.com/jinsight/.
[JPDA] Java Platform Debugger Architecture (JPDA), Available: “http://java.sun.com/products/jpda".
[Mullholland 1997] Mullholland, P., “Using A Fine-Grained Comparative Evaluation Technique to Understand and Design Software Visualization Tools”, Empirical Studies of Programmers, Seventh Workshop, pp. 91-108, Ablex Publishing, 1997.
[Netbeans] Netbeans IDE, Available, “http://www.netbeans.org/".
[Pennington 1987a] Pennington, N., “Stimulus Structures and Mental Representations in Expert Comprehension of Computer Programs”, Cognitive Psychology, Vol. 19, pp. 295-341, 1987.
[Pennington 1987b] Pennington, N., “Comprehension Strategies in Programming”, Empirical Studies of Programmers: Second Workshop, pp. 100-113, 1987.
[Smith and Munro 2002] Smith, M. P., and Munro, M., “Runtime Visualisation of Object Oriented Software”, 1st International Workshop on Visualizing Software for Understanding and Analysis, Paris, France, pp. 81-89, June 26, 2002.
[Storey et al 2000] Storey, M.-A. D., Wong, K., Muller, H. A., “How Do Program Understanding Tools Affect How Programmers Understand Programs ?”, Science of Computer Programming Journal, Vol 36, Issues 2-3, pp. 183-207, 2000 (paper first appeared 1998).
[von Mayrhauser and Vans 1993] von Mayrhauser, A., and Vans, A., “From code understanding needs to reverse engineering tool capabilities”, 6th International Conference on Computer-Aided Software Engineering (CASE), Singapore, July 19-23, 1993.
Spotlight on PPIGers
Would you like to tell other PPIGers how you are and what you are doing through the newsletter? If so, please e-mail chrisd(at)fdbk.co.uk.
Enda Dunican
We have a project starting in IT Carlow funded by the Higher Education Authority, the body in charge of all third-level education in Ireland.
The project is in the area of student retention. The funding provides a special office/lab with a number of PCs, and functions as a drop-in centre for students with problems in computer programming.
At this drop-in centre students can come to lecturers with programming problems. It occurs to me that this may be a very valuable resource in gathering details and categorising the main problems first year students have with computer programming.
If PPIG colleagues have an experience of dealing with students in this manner or if they have specialised in addressing novice programming problems they can contact me. Perhaps there may even be an opportunity for some collaboration with other educational institutes. I am open to suggestions.
Enda can be contacted by sending him a message using dunicane(at)itcarlow.ie
Linda McIver
Linda McIver missed the PPIG workshop this year, but in a good cause! Zoe Dianne McIver was born on March 25th at 8:36am. She was 4.35kg (9lbs 9oz), and has been thriving ever since (sitting comfortably on the high side of the growth curve, just like her mum!).
She’s a happy smiley baby, and she has Andrew and I under good control.
Rebecca Smith
Dear All,
Anyone who has heard me asking about how to get money for my research will be pleased to hear that I have finally received some funding, in the form of a University of Glasgow faculty studentship. Here’s a big thank you to Thomas Green who had some very useful suggestions for my application. And Thomas will be pleased to know that I have now read several of the papers he suggested I use as references!
Best wishes, Rebecca Smith.
Ray Waddington
I finished my visiting professor post at the University of Guelph, Ontario, Canada in 1992. For 10 years I worked in the software industry as a consultant, doing everything from y2k, project management to programming.
I have recently gone back to the academic world, taking an adjunct faculty position at Strayer University, where I teach computer science courses.
Most recently I founded The Peoples of The World Foundation, where I am a photoethnographer. The Foundation’s web site is at Peoples of the World
I am sure some of your readers will remember me.
Regards, Ray Waddington.
Musings from the Trenches
The unbearable lightness of errors
By Chris Douce
Due to various policy decisions recently made by a major operating system vendor, a number of different integrated development environments (IDE’s) were evaluated. These ranged ranged from those that were open source and freely available for use, through to very expensive (and supported) commercial equivalents.
One of the most striking differences between IDEs and their compilers was not the immediate differences in the screen layout - a change in design of a code explorer window - or the differences in the short-cut keys, but the differences in the compilation messages that were produced when code is compiled.
Leaving one IDE for another can be either a painful or enlightening experience. Not only do you loose the location of toolbar icons and menus learnt over several years, but also your ability to interpret the error messages that a new environment or compiler generates.
Rather than a producing a message stating, ‘semicolon missing at line n’, compilers often generate scroll-boxes filled with messages that have little bearing on what amounts to a very minor syntactical lapse.
I remember, as a beginner, being absolutely terrified by the screen scrolling past, generating acres of pages in response to an incredibly trivial error. My mentor sitting behind me would chuckle, wander over to my PC, move the cursor to a line that was close to the first error message and add my omitted semicolon, much to my astonishment.
Bracketing and braces are also common causes of a catastrophic cacophony of errors. A message telling you of an unexpected closing brace, really means that you have forgotten to put down an opening brace somewhere. Miss off a parameter and you may be told that you have an ‘unexpected “)”’ Cognitive psychology texts tell us that negative information is more difficult to comprehend.
When often presented with hundreds of small, all intricately related error messages, I get a ‘feeling’ for the original error, based upon the form that the messages take.
Changing your IDE changes the way you respond to your own mistakes. Your ’error schemas’ which fire when seeing the keywords similar to ‘unbounded’ or ‘inheritance’ may have to be reformed as you feel your way around your new IDE. At the same time you may even changing your model the language that you use.
Working with a compiler and responding to compilation messages can be viewed in terms of having a ‘conversation’ with a body of source code. On some occasions I have felt it helpful to deliberately introduce errors to observe the effects on some alien code.
I have renamed objects, classes and even files in moments of frustration to attempt to get snippets (or slices) of information about the inner workings of some undocumented software project undergoing maintenance.
When an IDE or compiler changes, so does its personality, so does a developers mode of communication with his or her unknown mass of symbols and instructions.
Are you working in industry and would like to tell us about an issue that you feel particularly strongly about? Is there something that you feel that the academic computer science, software engineering or human-factors communities should be addressing? If so, please do tell us!
Links Beyond
There are a huge number of conferences, journals and workshops that may be of interest to PPIG members. Since so many are relevant it may be difficult to know where to start searching. This section presents a few links to some of the journals that I have found useful.
Contemplating the cognitive needs of a programmer led me directly to the following journal:
This journal would prove to be rather fascinating. For a simple software engineer like myself who would become befuddled with reading articles about systems it would be refreshing to read about experiments performed on real people rather than machines:
Human-Computer Interaction is a popular topic amongst PPIGers for a number of reasons. Software development environments can be used to construct easy-to-use software packages, which may possess their own issues of usability.
Programming language (and software library!) design is also an issue that can lie within the area of HCI:
It would be impossible (and silly) to miss the famous (and nebulous) Communications of the ACM, a source of inspiration and information for a huge array of fields surrounding what may be termed ‘computer science’:
For those who have an interest in how engineering approaches could potentially be used to understand more about the application, use and development of computer systems and software development, the below transactions will be very familiar:
This journal appears to be obviously related to some of the Psychology of Programming topics, since a growing number of POP studies use existing systems and empirically analyse how programmers navigate, use and modify them.
In the journal below, the empirical studies may differ in methodology, but perhaps some of the observations and conclusions may be similar:
Here we have an interesting journal that brings disciplines together. In some cases software engineers and programmers are used to construct models to further understand what cognition is. There is more to Cognitive Science than initially meets the eye. If you are interested, please read on:
One enterprising soul has devised a ’top 10’ of classic Cognitive Science papers. Some are especially interesting, since they relate to novice-expert differences and diagrammatic reasoning, a topic that is of interest to those working with modeling languages such as UML, and those using ‘visual programming languages’:
Other journal titles that may also of interest includes Cognition, Brain and Cognition and Social Cognition.
Finally, spare a moment for those poor souls who have to straddle both the ‘code face’ and the ‘chalk face’. Computer science education is an activity that has to be undertaken throughout the life of a professional programmer. Perhaps here we will find some insights into what our students need:
Do you know of a journal that may be of interest to fellow PPIG members? If so, please tell us about it. Interested in writing a review, or perhaps you are an editor and would like to introduce your journal to us? Please feel free to send a message to chrisd(at)fdbk.co.uk
It's Doddery Fodder...but is it Art?By Frank Wales |
Supplementary Notes[1][1] These are like the kitchen of the academic discourse party; they're where all the interesting quips hang out. |
|
For some years now, I have been haunted[2] by a question I was asked once by a fellow PPIGlet: "Have you ever written a paper entitled 'Post-modernism explained by a software engineer'? Because I'd like to cite it if you have."[3] Since then, I've wondered what this paper might be about, and if I ever wrote it, whether it would be any good. I was reminded of this pending omission from my future emissions by these two essays which both compare programmers favourably with artists. The first article actually has "psychology of programming" in its title, so it must be right, while "Hackers and Painters" by Paul Graham contributes to the debate on whether programming is art or engineering firmly on the art side: |
[2] Well, not haunted exactly, since I don't believe in ghosts. Perhaps stalked. Or at least followed around from time to time and leered at in a funny way. [3] To protect the identity of this person, who now seems to have forgotten asking such a question, I won't use his real name. Instead, I'll refer to him as "Allan Blackwell". |
|
If I can ever find someone at least vaguely authoritative who can explain Post-modernism to me without first apologising for why their definition isn't a very good one, I might be able to make progress in writing my paper. But funnily enough, as I study art more[4], I find "vague authority" seems to sum up much of modern art pretty well anyway, so maybe I'm being just too enlightenment-oriented when I expect a simple answer that I can understand. |
[4] And yes, in my spare time I really am an arts student. "Know thine enemy", as someone once said. |
|
After all, the history of art is a series of oscillations between simplification & distillation and exploration & complexification, with the Classical and Modernist eras examples of the former, and the Baroque and Post-modern examples of the latter. [5] |
[5] In physics, this important technique is called "proof by blatant assertion". |
|
It is very tempting to try to fit the history of programming into this model, with (say) structured programming and design patterns analogous to Classicism and Modernism, and things like the Web and Perl representing the Baroque and Post-modern[6]. Maybe we could even pretend that Sourceforge represents the world's largest collection of found art[7], while Google is the world's biggest collection of repurposed content[8]. And maybe this site, dedicated to discussing tiny pieces of free code, will act as a microcosm of that pretense: |
[6] Hence the phrase "If it ain't Baroquen, don't fix it." [7] "Found art" appears to be a declaration by an artist that his immediate surroundings had more talent than he did. [8]"Re-purposed content"appears to be a declaration by a developer that her immediate predecessors had more talent than she did. |
|
More interestingly, sites like this perhaps show the essential Post-modernism of the whole free software movement, which avowedly encourages copying, adaptation and recombination. Speaking of recombination, this announcement from the Royal College of Art mooting some biological software muckaboutery fits right in: |
|
|
Perhaps it's just me, but the idea of inserting the entire human genome into that of a tree strikes me as both massively ill-conceived and perhaps even ludicrously dangerous[9]. Anyway, I'm thinking that I should just appropriate[10] Larry Wall's paper "Perl: the first post-modern programming language" to get me started, and then toss in some verbiage from the Post-modernism generator to lend gravitas, or at least promote a sense of intellectually-outclassed bewilderment in the reader[11]: |
[9] But then, perhaps I know just enough about genetics and software to imagine the failure scenarios, but not enough about conceptual art to see why this isn't just genetic engineering by cut-and-paste. [10] "Appropriation" is the art-world term for what most intellectual property lawyers would call "stealing". See: these links [11] Cynicism like this is very Post-modern too, I'm told. |
|
Many programmers seem attracted to perl by its maxim "There's more than one way to do it", which is antipathetic to many specialised languages, which might have the maxim "There's nearly one way to do it, but not quite.". Perl, along with other scripting languages, certainly polarises the armchair software engineers who've wandered over from the web development world: |
|
|
Whether perl's imminent re-design will enhance the language or dehance[12] it remains to be seen, but it'll clearly provide much fodder for future arguments between aficionados of dense syntax and fans of semantically significant quantities of white-space: One of perl's clear strong points is its lack of shame in stealing (sorry, appropriating) ideas and ways of doing things from other languages, and it's perhaps this that's led it to become an important glue language, especially in these web-enabled times when the hard problems seem to be festering in the cracks and crevices of the virtual world. |
[12] What do you mean, 'dehance' isn't a word? You understood it, right? Next, you'll be telling me that 'pessimal' isn't the opposite of 'optimal'. |
|
Which brings me back to XML again[13]. This presentation opines that XML is awful, but inevitable despite its awfulness: |
[13] Which, due to a technical oversight, was completely missing from my previous column |
|
And its author is not alone in finding fault with this programming generation's most over-achieving technology: |
|
|
But so far, I haven't found a document about XML that matches the comprehensive pasting given to Unix (and its known associates) in The Unix-Haters Handbook, now available in its entirety online[14]: But that's enough non sequiturs for today. |
[14] Apart from the Unix barf bag that came with the original book. |
|
One of the reasons for disliking the "programming as art" opinion is that it makes the interviewing process a lot harder. But there are still some software domains where the environment applies enough selection pressure to make questions with right answers useful, such as embedded systems development: To test those eager candidates who've memorised the Frequently Asked Questions from comp.lang.c, here are the Infrequently Asked Questions: |
|
|
And if you find that your interview candidates have low SAT scores, perhaps they're just showing off how much they do know by deliberately answering everything wrong, like this guy did: |
|
|
Still, I know a few managers who much prefer to treat software developers as interchangeable code-monkeys, so they might be dismayed to find out that code monkeys aren't so interchangeable after all. At least, if Primate Programming Inc is to be believed: Now that people outside of software development are actually taking the whole "software as art" thing more seriously, maybe this shows that programming is sinking into the heads of enough artists to start some genuinely new things: |
|
|
Perhaps one way to resolve the art versus engineering dichotomy is to consider it as false as the dichotomy between plumbing [15] and fashion [16], and instead accept that there are different aspects to programming [17] that sometimes look arty, and sometimes engineeringy[18]. |
[15] Essential, hidden, stable. [16] Inessential, visible, transitory. [17] As opposed to aspect-oriented programming, which is now apparently patented, and therefore potentially a lot harder to use: United States Patent: 6,467,086 [18] You want precision? Ask an engineer. You want vagueness? Ask an artist. You want both? Ask a programmer about deadlines. |
|
While technologists can clearly learn many things from artists, there are at least some fundamental things they still have to learn from us. For example, that the primary colours are not red, blue and yellow[19]. |
[19] For those of you who think this is right, take a close look at the dyes in a full-colour CMYK print cartridge. And if you think 'cyan' and 'magenta' are really just different shades of 'blue' and 'red', then you need more help than I can offer. |
|
But with the Net now pretty well-established as the mediator of, and the reason for, many of the most interesting developments in programming, maybe I should be planning to write a paper about "Post-modemism"[20] instead. After all, I just have to make this thrilling new concept vague enough to be understood clearly by anyone, and my place in History[21] will be assured. |
[20] If you think this says "Post-modernism", you need to look at it more closely. I hereby declare this to be the world's first typogronym, which is a new word that, when printed with the right typeface, closely resembles another word. Maybe I should patent it. [21] Or at least my place in Geography. |
Frank Wales
frank(at)limov.com
www.limov.com/frank.lml
Acknowledgements
Many thanks go to Frank Wales for the assistance he has given during the production of this newsletter.